Replication Fields
Replication Fields
A replication key is a unique identifier or field in a source table that helps Daton keep track of the changes in the data since the last replication.
While integrating a source, selecting a replication field is essential because it determines how Daton identifies and replicates new or modified rows from the source connector.
When you select a replication field, Daton uses it to keep track of the data changes in the source since the last replication. It enables Daton to efficiently extract only the new or modified rows and update the destination data warehouse accordingly. This process helps in reducing the data transfer and storage overhead, ensuring optimal use of resources and minimizing costs, especially in Daton's billing model. It's worth mentioning that, the data is fetched and loaded in batches as this approach optimizes performance and ensures smooth data transfer.
There are two common methods of replication supported by Daton:
-
Replication by ID:
This method relies on a unique, auto-incrementing identifier (e.g., "transactionid", "rowid") that determines the number of records updated in a table, often called an ID field. When you choose this option, Daton will use the field to identify new rows that have been inserted since the last replication. It will replicate only the rows with higher ID values than the last one processed. It is ideal when the source does not have a dedicated date or time accordance, and the uniqueness of the ID field can be relied upon to identify changes.
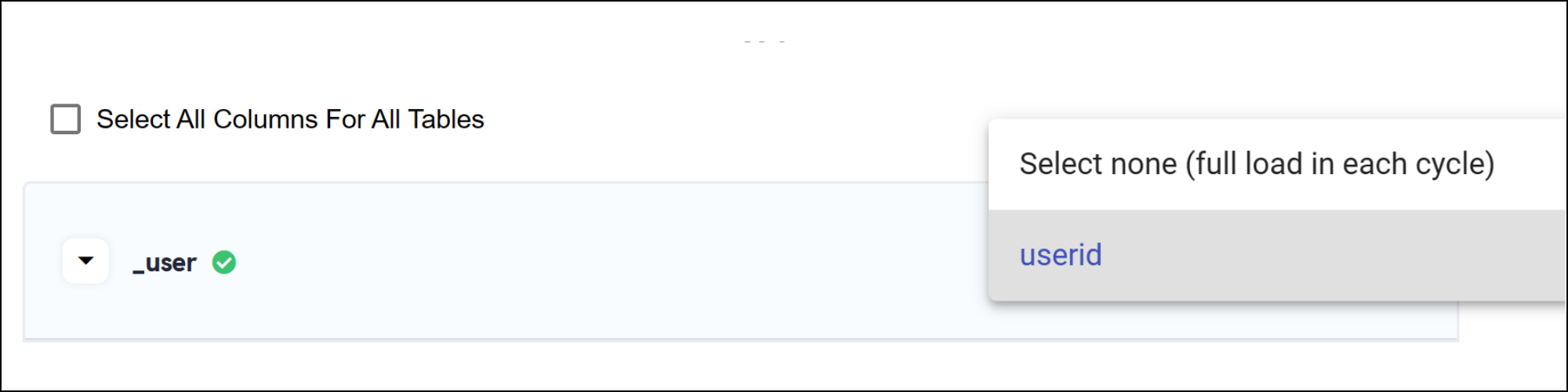
-
Replication by Timestamp:
This method uses a timestamp/date/datetime field (e.g., "created_at" or "datetimeofcreation") to track changes. When you select this option, Daton will use the field to identify new or updated rows based on their creation or modification time or date. It will replicate only the rows with timestamps greater than the last replication time or date respectively.
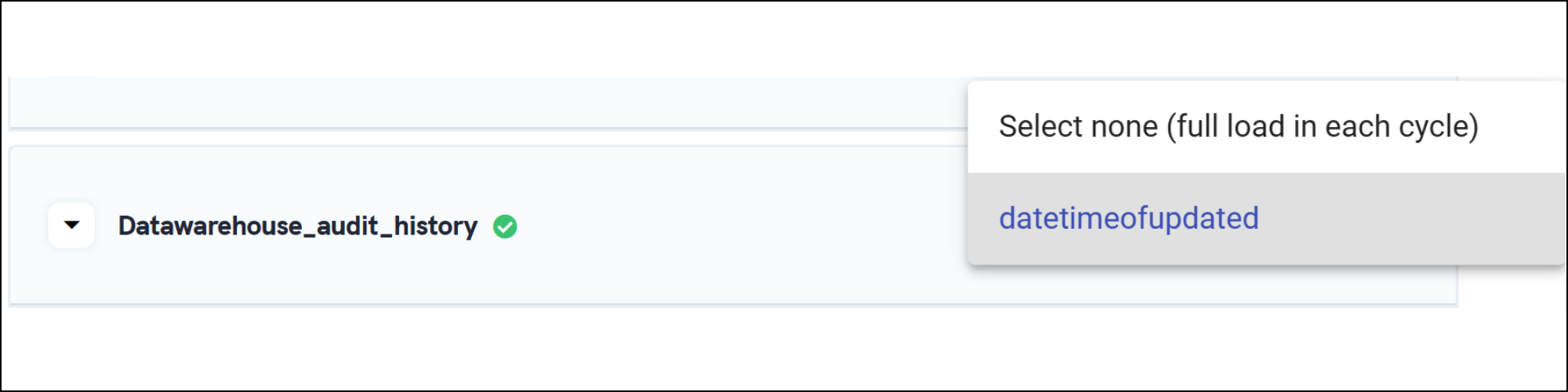
Selecting 'None' as a Replication field
It is important to note that selecting 'None' for the replication field may cause inconvenience as it would trigger a full data load every time, leading to higher resource consumption and longer replication times that eventually impacts billing.
In some instances, tables in the connector might have default settings for a full load only, making them non-editable to select a replication field.
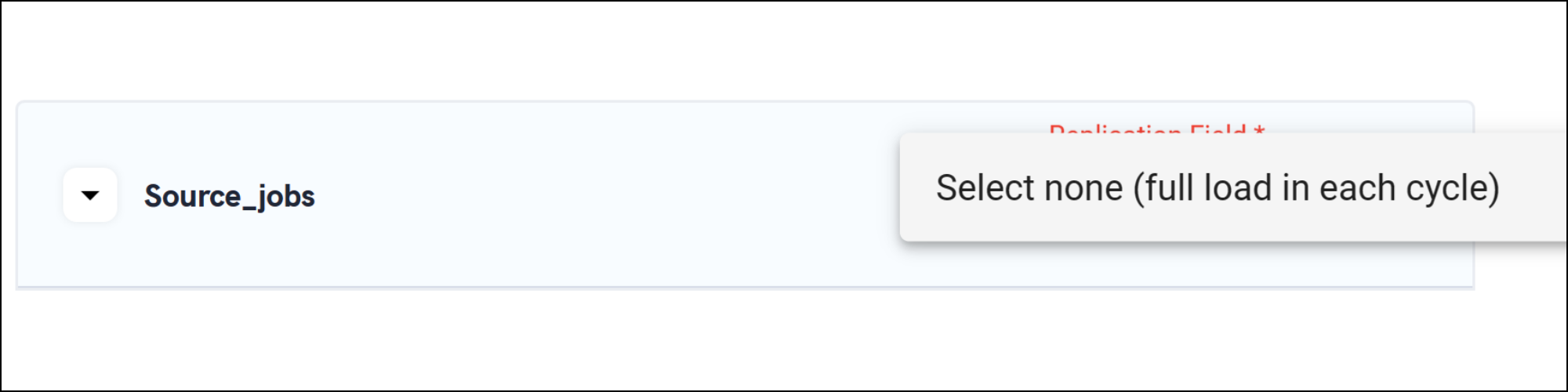
In such cases, especially when it is a database source, it's best to evaluate the data size and frequency of changes. It is recommended to customize the replication frequency and replication start date of each desired table separately. This functionality can be found under the advanced settings of every selected table.
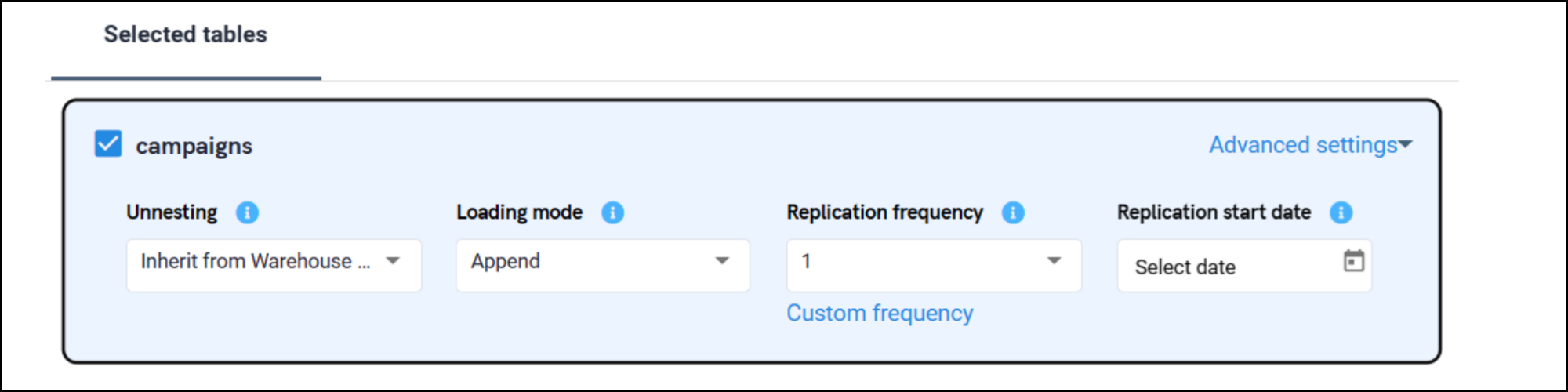
For each job, we now retain the last recorded data. This improvement ensures that job-specific data regarding the latest record is visible. Clients can access this enhancement in the user interface by selecting the job bar in an active integration. Consequently, they can verify the uppermost value of data that has been replicated for a particular job. This feature provides users with a more comprehensive understanding of the replication process on a per-job basis.
Choosing the appropriate replication method depends on the data and schema of the source database. If the connector has a reliable ID field that increments with each new row, replication by ID is a suitable choice. On the other hand, if there is a field that regards time or date that accurately captures row modifications, replication by Date/DateTime/Timestamp is a more efficient option.
Selecting the right replication field is crucial for proper data synchronization between the source, Daton, and the destination, ensuring only incremental changes are captured and reducing unnecessary data duplication.